01 — Context
The problem
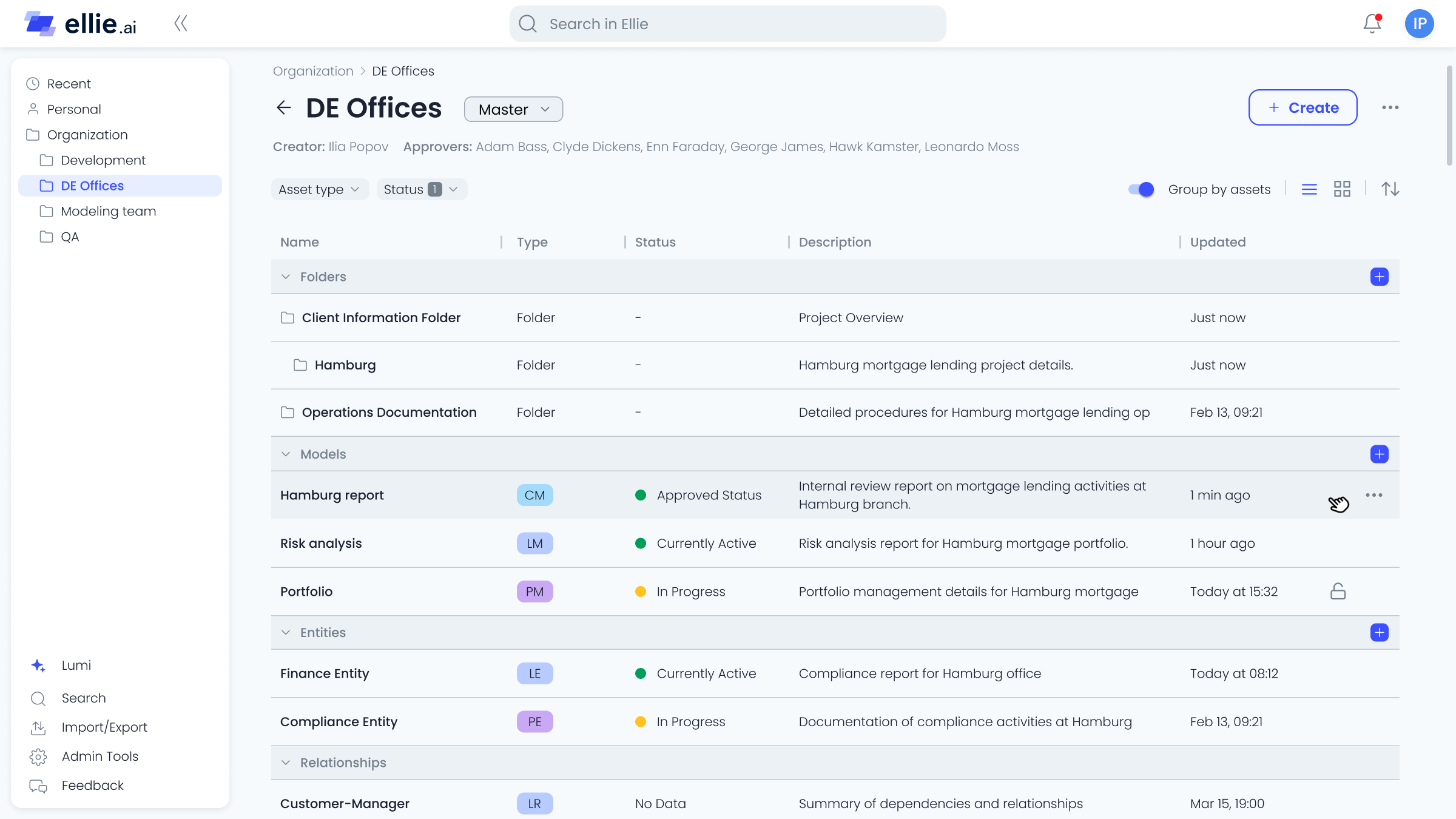
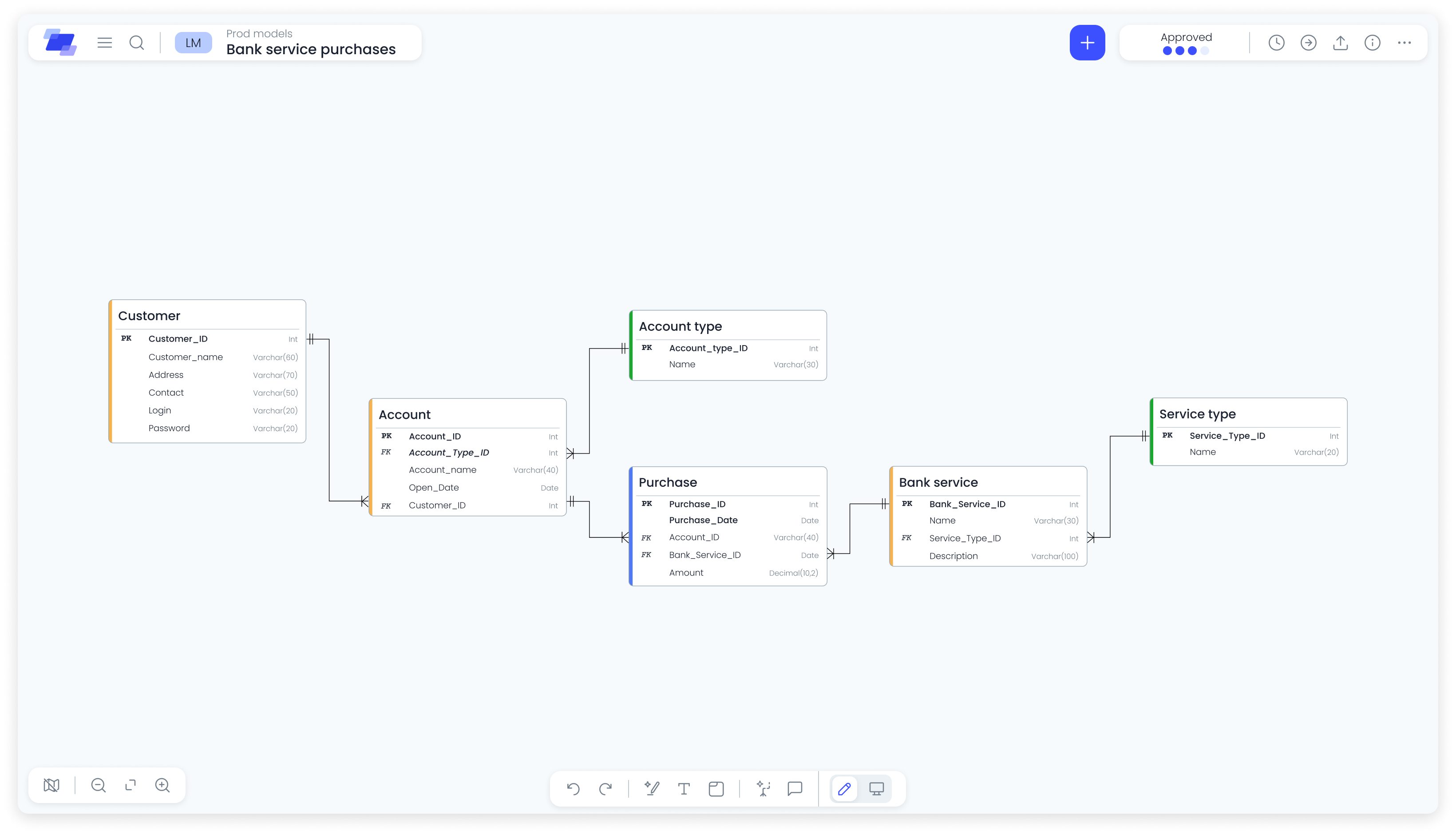
Ellie.ai is a collaborative data modeling tool used by data engineers, architects, and analysts to design and document database schemas. As the product started attracting enterprise interest, the existing free-form canvas — built for solo users — began to break down under team conditions: no access control, no review process, no way to manage change across large, complex models.
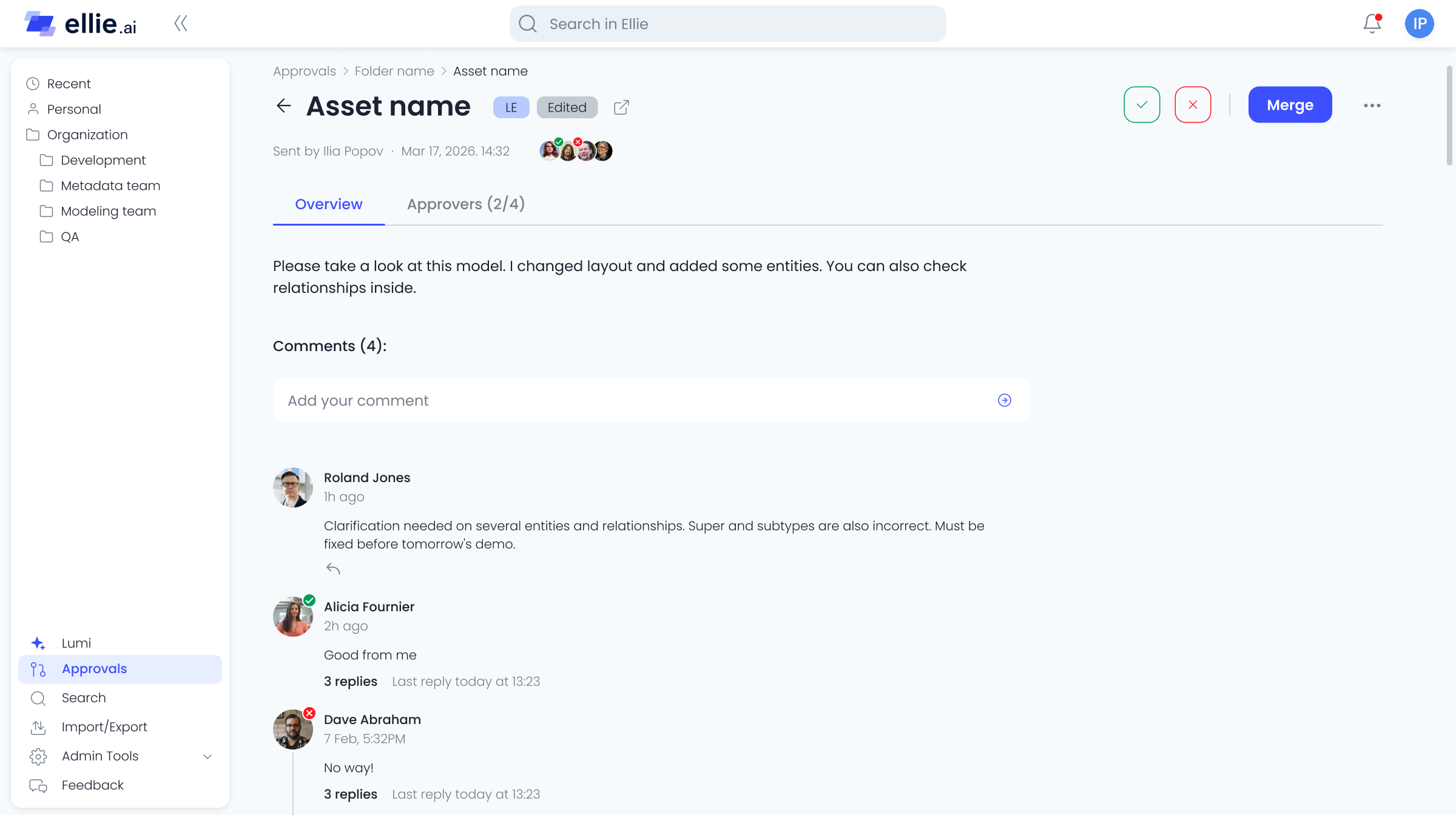
- 01 Any team member could edit any part of the model at any time — there was no concept of ownership, review, or approval.
- 02 Enterprises needed audit trails and governance workflows before they could sign contracts. We had neither.
- 03 Large schemas became impossible to navigate — hundreds of tables with no grouping, filtering, or contextual structure.
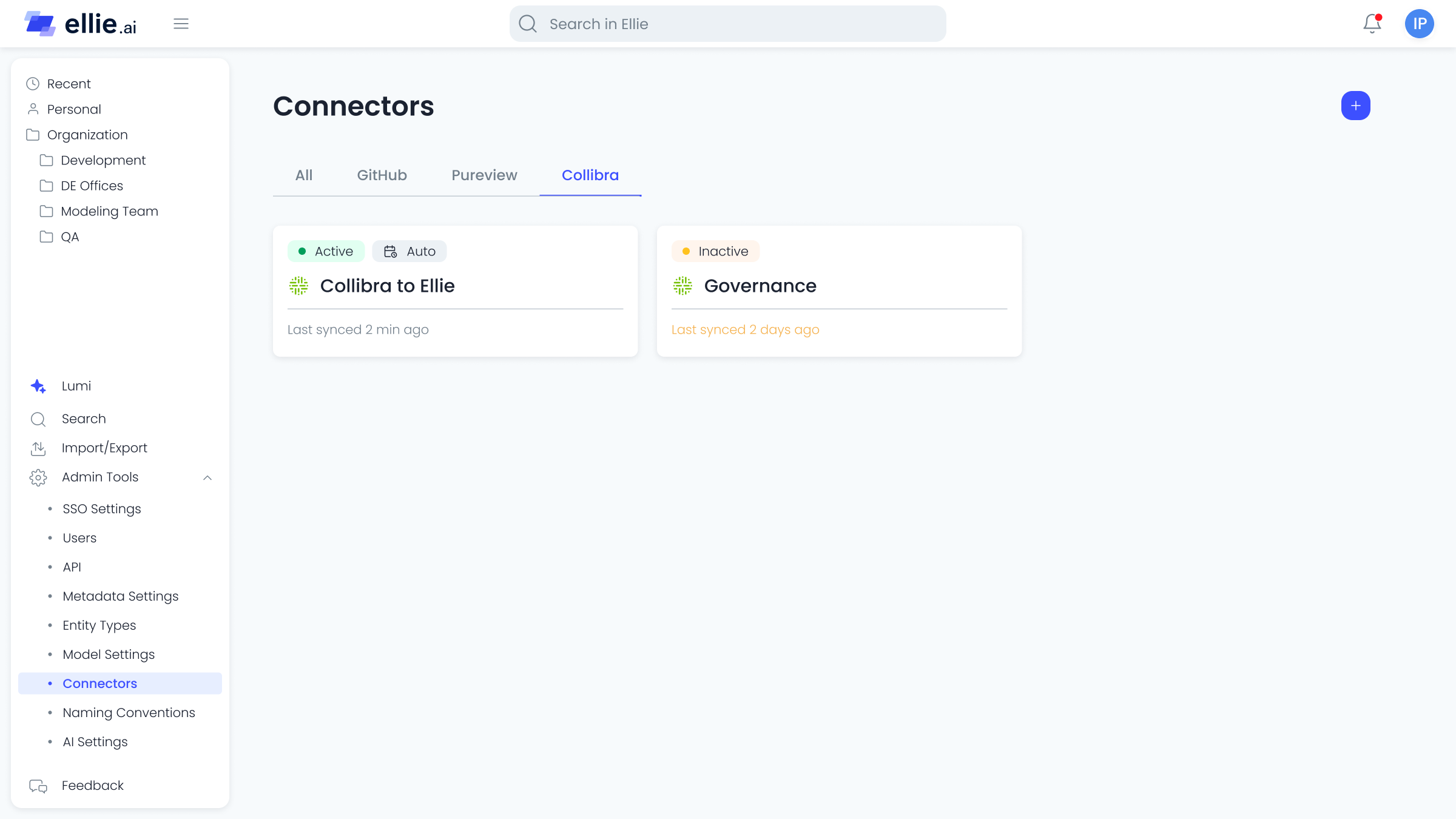
- 04 Data sources lived outside the tool, so models were always partially stale. There was no way to sync or validate against real data.